11 Best Tools for Data Extraction Automation in 2025

In a world driven by data, the ability to quickly and accurately extract valuable information is a competitive necessity. From market research and lead generation to price monitoring, businesses rely on a constant stream of fresh data to make critical decisions. Manual extraction, however, is notoriously slow, prone to human error, and simply unsustainable at scale. This is where data extraction automation transforms a tedious, resource-intensive task into a streamlined, powerful, and strategic process.
This shift is about more than just scraping websites; it’s about creating intelligent, automated systems that gather, structure, and deliver ready-to-use data directly into your workflows. This comprehensive guide serves as your deep dive into the world of data extraction automation. We will explore its core concepts, its transformative impact across various industries, and most importantly, provide a detailed analysis of the best tools available today.
Our goal is to help you find the right solution for your specific needs, whether you're a market research analyst, an e-commerce manager, or a data journalist. For each of the 11 platforms we cover, from simple no-code browser extensions to powerful enterprise-grade platforms, we provide a hands-on review, screenshots, direct links, and practical use cases. We will examine the specific strengths, real-world applications, and honest limitations of tools like PandaExtract, Apify, Bright Data, and more. This resource is designed to cut through the noise and equip you with the insights needed to select and implement the perfect data extraction automation tool for your projects.
1. PandaExtract - Ultimate Web Scraper
PandaExtract establishes itself as a premier choice for data extraction automation, offering a powerful yet remarkably accessible no-code solution. It operates as a Chrome extension, democratizing web scraping for professionals who need structured data without the steep learning curve of programming. Its core strength lies in an intelligent selection tool that simplifies the entire process into a few clicks, making it an ideal entry point for users new to data extraction and a significant time-saver for seasoned experts.
The platform's design philosophy centers on user empowerment. Whether you're a market researcher tracking competitor pricing, a sales team building lead lists, or an e-commerce manager analyzing product catalogs, PandaExtract provides the tools to get the job done efficiently. Its intuitive point-and-click interface allows users to effortlessly select and extract lists, tables, and even data spanning multiple pages.
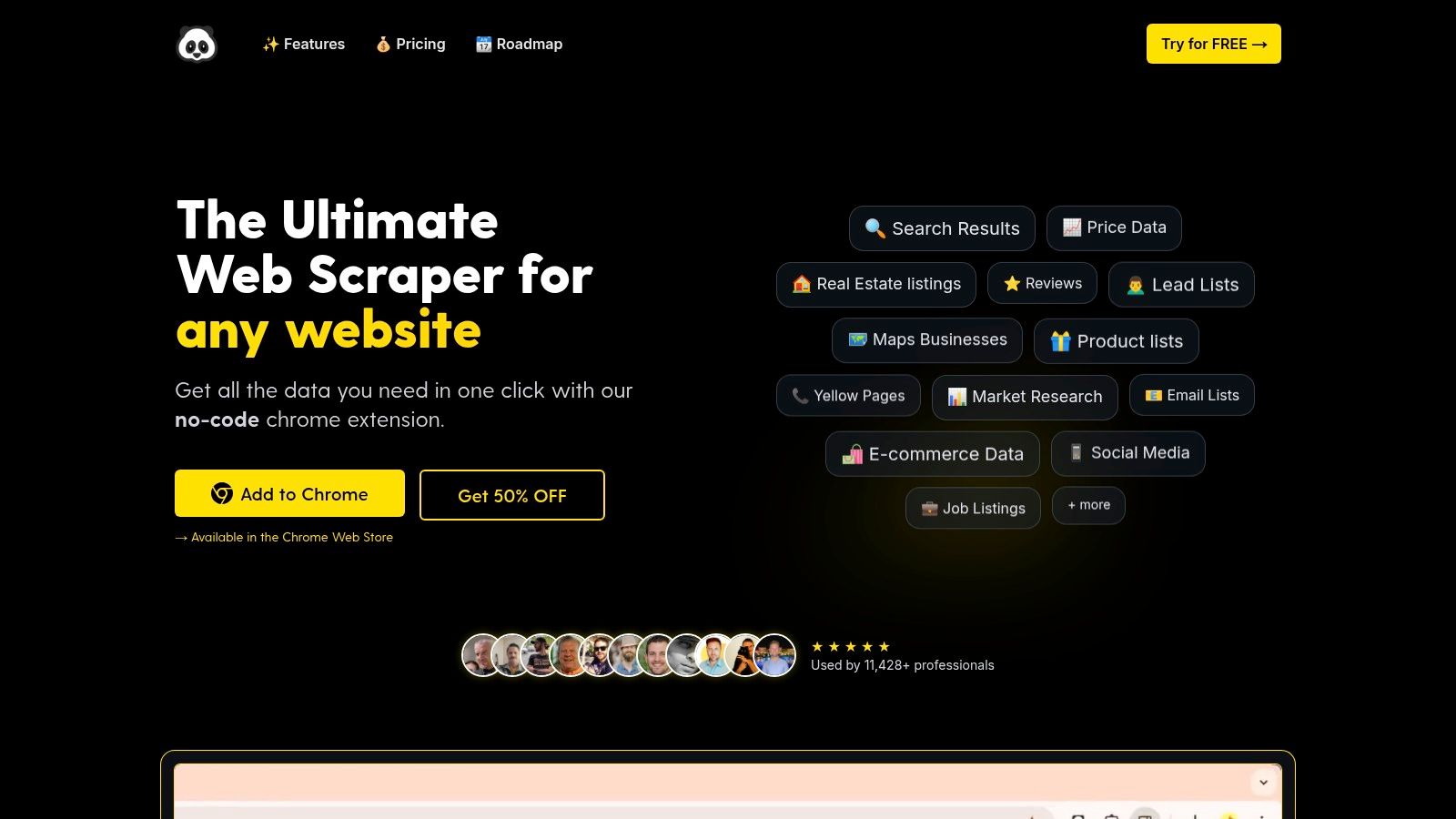
Comprehensive Feature Set
PandaExtract stands out with a robust suite of features designed for both simple and complex scraping tasks. Its versatility makes it a strong, well-rounded tool for diverse data extraction automation needs.
- Bulk & Automated Extraction: Users can upload a CSV file with hundreds of URLs to perform large-scale extractions. The deep subpage scanning feature automatically navigates to and scrapes data from linked detail pages, a crucial function for complex sites like e-commerce or directories.
- Built-in Data Management: A standout feature is the integrated spreadsheet view. Before exporting, you can clean, filter, and edit data directly within the extension, ensuring the final output is refined and ready for analysis.
- Flexible Export Options: Data can be seamlessly exported to CSV, Excel, and Google Sheets, or simply copied to the clipboard for quick use. This flexibility supports various data workflows.
- Advanced Scheduling & Integration: For true automation, tasks can be scheduled to run in the cloud, ensuring data is collected consistently without manual intervention. Webhook and n8n integrations further extend its capabilities, allowing it to connect with other business applications.
Practical Use Cases and Implementation
The real-world applications of PandaExtract are vast. For instance, real estate professionals can systematically pull property details from multiple listing sites, a process detailed in their guide on how to scrape real estate listings from PandaExtract.com. Marketers can use it for lead generation by harvesting contact information, while e-commerce teams can monitor competitor pricing and product details. The setup is straightforward: install the extension, navigate to a target website, and use the selector to define the data you need.
Why It Stands Out
- Pros:
- No-Code Simplicity: Its hover-and-click interface is exceptionally user-friendly.
- Versatile Capabilities: Extracts lists, tables, emails, and images with precision.
- Powerful Automation: Features like CSV uploads, deep scanning, and cloud scheduling are built for scale.
- Integrated Data Cleansing: The built-in spreadsheet is a significant advantage for data quality.
- Cons:
- Browser Limitation: Currently available for Chrome and Chromium-based browsers (Edge, Brave), which may not suit all users.
- Roadmap Features: Some advanced functionalities like "save & re-run" are in development and not yet available.
For those looking to streamline their data gathering workflows, you can download the PandaExtract Chrome extension and start automating your data extraction tasks today.
Website: https://pandaextract.com
2. Apify
Apify positions itself as a powerful, all-in-one platform for web scraping and data extraction automation, catering to both developers and users without extensive coding skills. Its key differentiator is the "Apify Store," a marketplace hosting over 2,000 pre-built scraping tools, known as "Actors." This massive library allows users to quickly find and deploy solutions for common tasks like extracting product data from e-commerce sites, monitoring social media trends, or gathering real estate listings.
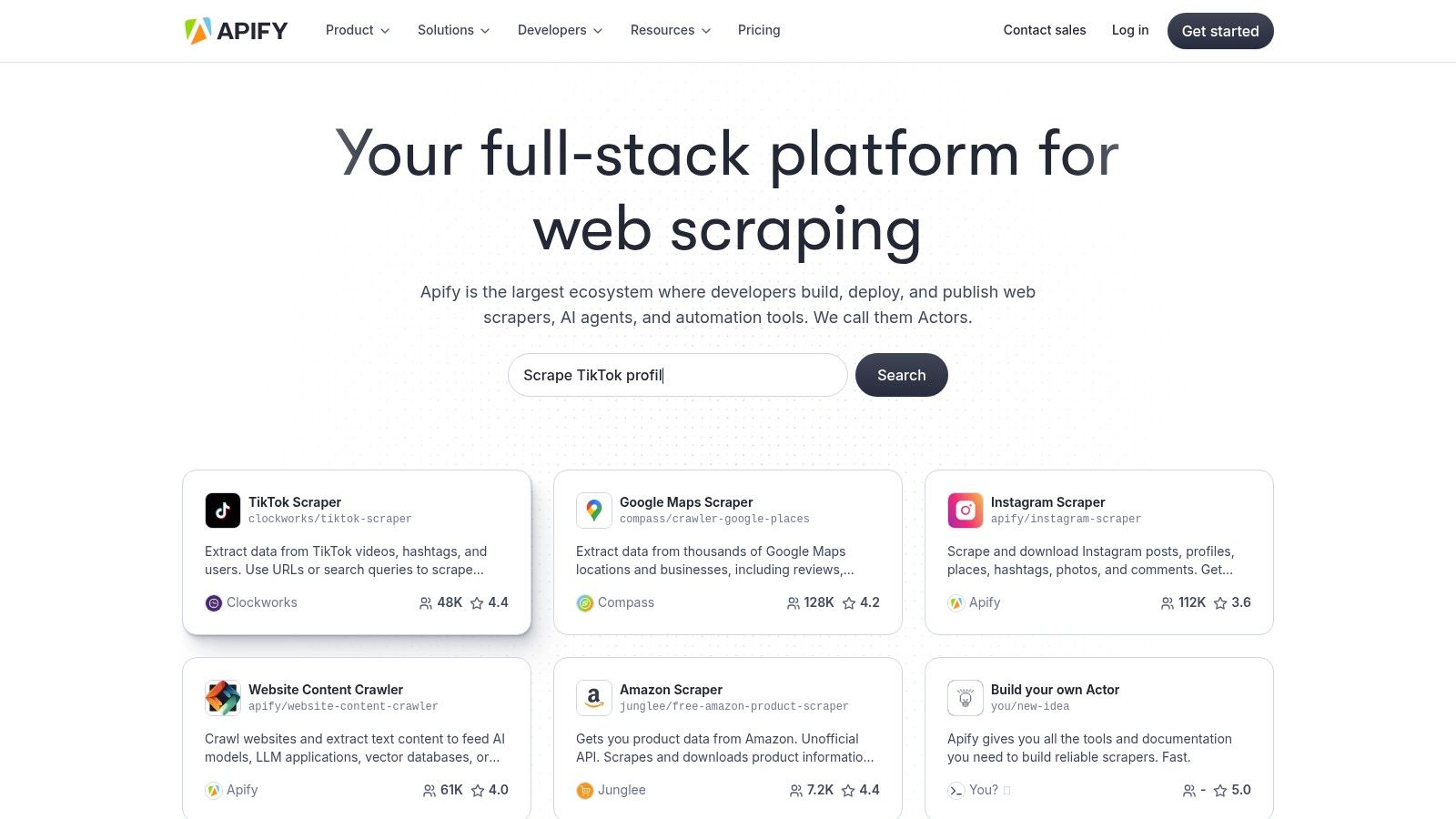
This actor-based model provides immediate value, but Apify also offers deep customization for technical users. Developers can build their own Actors using open-source libraries (like Crawlee) and run them on Apify's scalable cloud infrastructure, which handles proxy management, headless browser rendering, and parallel processing. This hybrid approach makes it an excellent choice for teams that start with no-code tools and gradually move toward more complex, custom data extraction automation projects.
Core Features & Implementation
- Pre-built Scrapers: The Apify Store is the platform's standout feature. You can find ready-made Actors for scraping Google Maps, Instagram, Amazon, and thousands of other websites, saving significant development time.
- Scalable Infrastructure: Apify manages the complexities of large-scale scraping, including rotating proxies and running headless Chrome browsers, allowing you to focus on the data logic.
- Developer-Friendly Tools: It provides robust APIs and open-source libraries for building custom solutions, offering full control over the scraping process.
- Pricing: Apify offers a free tier with limited platform credits, perfect for small projects or testing. Paid plans are usage-based, scaling with the number of Actor runs and compute units consumed. This can become costly for very high-volume tasks.
Key Insight: While the pre-built Actors are a major draw, Apify’s true strength lies in its scalability. It’s a platform designed to grow with your needs, from simple extractions to enterprise-level data operations. For simpler, browser-based tasks, a tool like the Ultimate Web Scraper Chrome extension can be a great starting point.
Website: https://apify.com/
3. Octoparse
Octoparse democratizes data extraction automation by offering a powerful, no-code visual interface that empowers users without any programming background. Its main advantage is the point-and-click workflow designer, which simulates human browsing behavior to navigate websites, handle logins, fill out forms, and extract data from dynamic pages loaded with JavaScript. This makes it an ideal solution for market researchers, e-commerce managers, and sales teams who need structured data quickly.
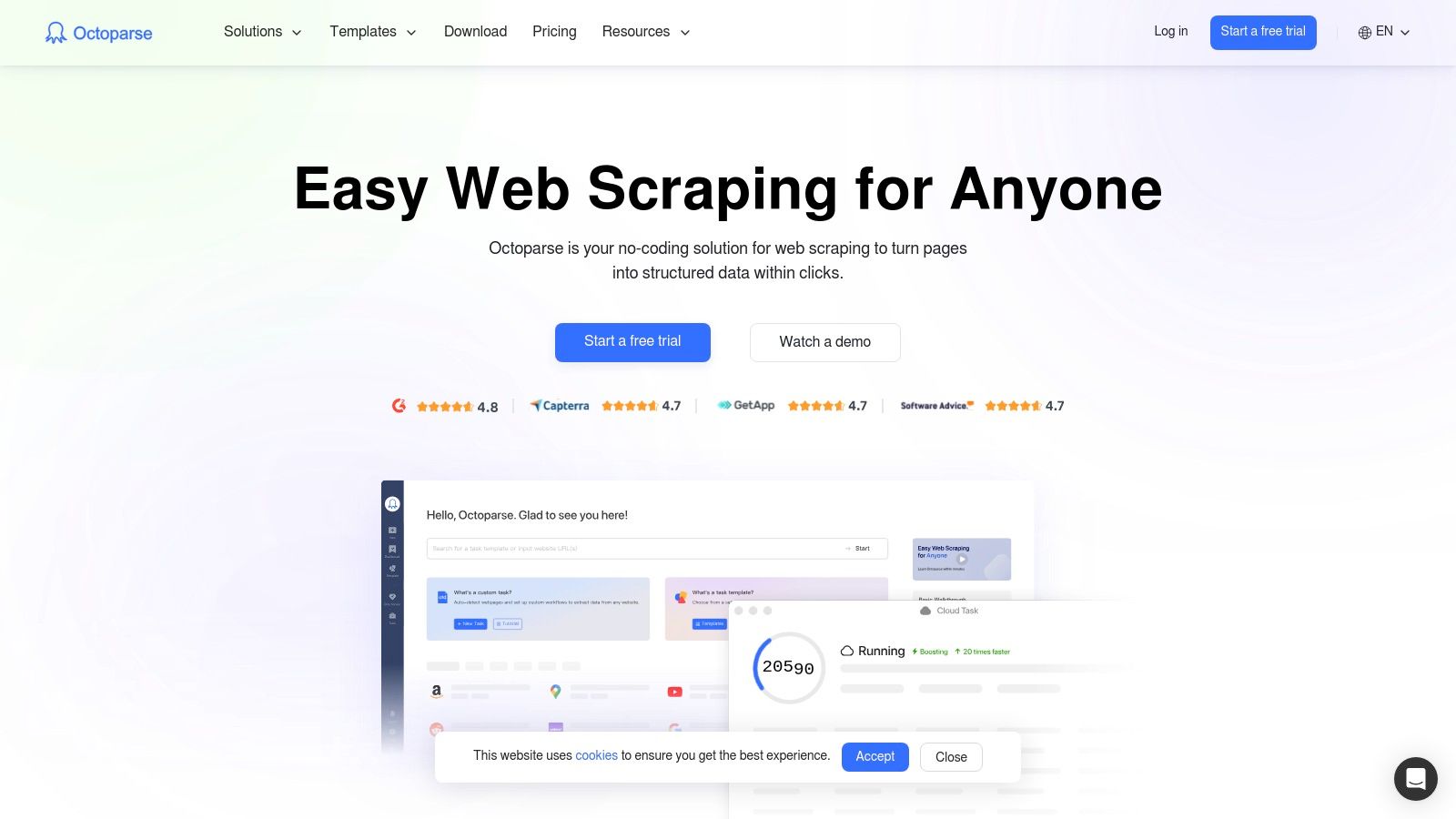
The platform stands out by offering both local and cloud-based scraping. Users can build and test scrapers on their own computers with the desktop application and then deploy them to the Octoparse cloud for scheduled, high-volume extraction. This dual-mode approach provides flexibility, allowing for rapid prototyping locally before scaling up operations. For those new to the field, exploring a range of web scraping tools can provide context on which approach best fits their project's complexity.
Core Features & Implementation
- Visual Workflow Designer: Build complex scrapers by simply clicking on the elements you want to extract. The tool automatically generates the necessary steps, which can be easily modified.
- Cloud & Local Extraction: Run tasks on your local machine for free or leverage the cloud platform for 24/7 scraping, automatic IP rotation, and scheduled runs.
- Pre-built Templates: Octoparse offers a library of templates for popular sites like Amazon, Yelp, and Twitter, enabling users to start collecting data in minutes.
- Data Handling: It effectively scrapes sites with infinite scrolling, dropdowns, and pagination, exporting clean data to formats like CSV, Excel, and JSON, or directly to a database via APIs.
- Pricing: A generous free plan is available for small projects, which is great for learning. Paid plans are tiered based on the number of concurrent tasks and cloud speed, making it accessible for various budgets.
Key Insight: Octoparse excels at bridging the gap between simple browser extensions and complex coding frameworks. It provides a robust, scalable environment for non-developers to perform sophisticated data extraction automation without writing a single line of code. For one-off, browser-based tasks, you can download our chrome extension as a simpler alternative.
Website: https://www.octoparse.com/
4. ParseHub
ParseHub is a powerful visual data extraction tool designed for users who need to scrape modern, dynamic websites without writing any code. It stands out by offering a desktop application that allows you to build scrapers through an intuitive point-and-click interface. This makes it particularly effective for handling sites that rely heavily on JavaScript, AJAX, or infinite scroll, which can often challenge simpler data extraction automation tools.
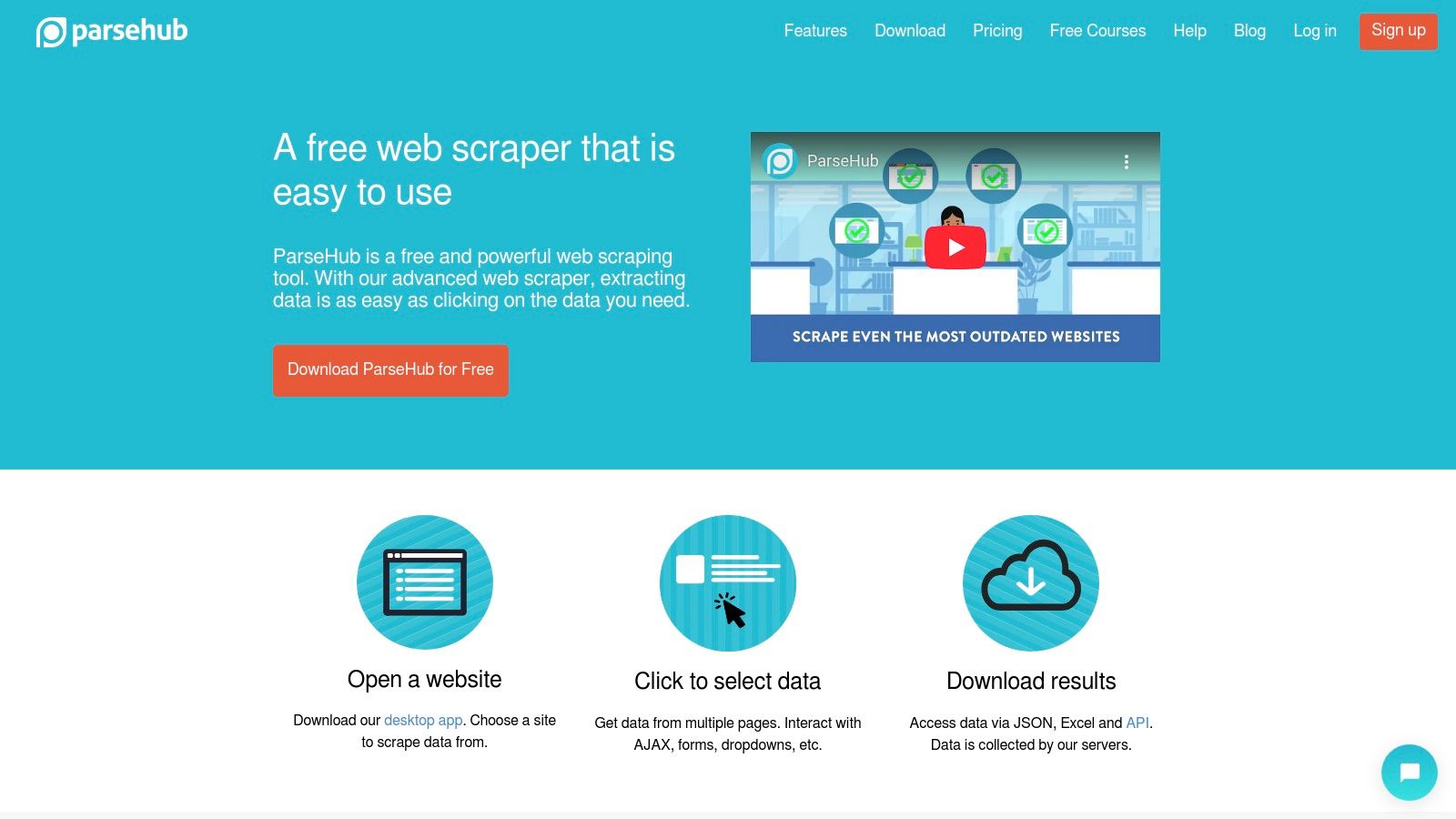
The platform operates on a hybrid model where you configure your extraction project locally on your machine and then run it on ParseHub’s cloud servers. This approach allows for complex logic, such as navigating drop-down menus, handling logins, and dealing with pagination. It’s an excellent choice for market researchers, e-commerce managers, and data journalists who need granular control over data collection from interactive web pages but may not have programming expertise.
Core Features & Implementation
- Visual Point-and-Click Interface: Users train the scraper by simply clicking on the data elements they want to extract, making the setup process highly intuitive for non-developers.
- Handles Complex Websites: ParseHub is built to navigate and scrape interactive sites, including those with forms, infinite scroll, and nested data structures.
- Advanced Logic: It supports conditional logic ("if" statements) and regular expressions, enabling you to clean and filter data with precision during the extraction phase.
- Pricing: ParseHub provides a generous free tier that is fully functional but limited in speed and the number of pages per run. Paid plans offer IP rotation, increased crawling speeds, and project storage.
Key Insight: ParseHub's strength is its ability to democratize the scraping of complex, dynamic websites. It empowers non-technical users to build robust data extraction automation workflows that would otherwise require custom scripts. For very simple, static page scraping, a browser-based tool like our Chrome extension can offer a quicker solution.
Website: https://www.parsehub.com/
5. Nanonets
Nanonets takes a different approach to data extraction automation, focusing primarily on unstructured and semi-structured documents rather than just websites. It leverages powerful AI and Optical Character Recognition (OCR) to pull data from PDFs, invoices, receipts, ID cards, and emails with remarkable accuracy. This makes it an indispensable tool for businesses looking to automate their document processing workflows, such as accounts payable, customer onboarding, or logistics.
The platform's key differentiator is its adaptive learning capability. While Nanonets comes with pre-built models for common document types, users can easily train custom models on their specific layouts without writing any code. You simply upload a few examples and highlight the data fields you need to extract. The AI learns from your input, improving its accuracy over time. This no-code, AI-driven process democratizes document data extraction for teams without specialized technical skills.
Core Features & Implementation
- Advanced OCR: Nanonets excels at converting scanned documents and images into structured, machine-readable data, handling complex tables and varied layouts.
- No-Code Workflow Builder: Users can design end-to-end automation pipelines, from receiving a document via email to extracting data and exporting it directly to a CRM, ERP, or database.
- AI-Powered Learning: The platform allows you to train and retrain models on your specific documents, ensuring high accuracy even with unique or inconsistent formats.
- Pricing: Nanonets provides a free plan to get started, with paid plans based on the number of documents processed and features needed. The pay-as-you-go model can become costly for organizations with very high document volumes.
Key Insight: Nanonets is the go-to solution when your data extraction needs go beyond web pages and into the world of internal documents. Its strength lies in turning messy, unstructured PDFs and images into clean, actionable data. For straightforward web-based data tasks, you can download our Chrome extension as a more direct solution.
Website: https://nanonets.com/
6. Hevo Data
Hevo Data is a no-code data pipeline platform specializing in integrating and moving data from disparate sources into a centralized data warehouse. While not a web scraper in the traditional sense, it plays a critical role in data extraction automation by connecting to over 150 sources, including SaaS applications, databases, and marketing platforms. Its core strength is providing a reliable, automated bridge to pull data from these APIs and load it into destinations like Snowflake, BigQuery, or Redshift for analysis.
This makes Hevo an ideal solution for businesses that need to consolidate data from various operational tools, such as CRMs, advertising platforms, and payment gateways. The platform automates the tedious ETL (Extract, Transform, Load) process with features like automated schema mapping and real-time replication. This ensures that business intelligence teams always have access to fresh, structured data without writing or maintaining complex integration scripts, allowing them to focus on deriving insights rather than managing data pipelines.
Core Features & Implementation
- Extensive Connector Library: Hevo supports over 150 data sources, including popular services like Salesforce, Google Analytics, and Stripe, making it easy to unify business data.
- Automated Schema Mapping: The platform automatically detects the schema of incoming data and maps it to the destination warehouse, adapting to changes without manual intervention.
- Real-time Data Integration: It offers real-time or near-real-time data replication, ensuring that your data warehouse is consistently up-to-date for timely analysis.
- Pricing: Hevo provides a free plan for up to one million events, suitable for small-scale integrations. Paid plans are based on the volume of events and offer more advanced features, which can become costly for larger enterprises.
Key Insight: Hevo Data excels at the "last mile" of data extraction automation, moving structured data from APIs to warehouses. It's not for scraping public websites but is essential for creating a single source of truth from your internal and SaaS tools. For unstructured web data, a tool like our Chrome extension is a perfect complement.
Website: https://hevodata.com/
7. Bright Data
Bright Data is renowned for its enterprise-grade web data platform, focusing heavily on providing the underlying infrastructure needed for successful large-scale data extraction automation. Its core strength lies in its vast and reliable proxy network, which is arguably one of the most comprehensive in the industry. This makes it an essential tool for businesses that need to bypass sophisticated anti-bot measures, geographic restrictions, and IP blocks to ensure high data collection success rates.
Unlike platforms centered on no-code interfaces, Bright Data provides the heavy-duty tools that power complex scraping operations. It offers a Web Scraper IDE for developers to build and deploy custom collectors, alongside a powerful Web Unlocker that handles CAPTCHAs and browser fingerprinting automatically. This focus on overcoming collection barriers makes it a go-to solution for companies extracting competitive intelligence, financial data, or search engine results where failure is not an option.
Core Features & Implementation
- Premium Proxy Networks: Offers an extensive range of residential, ISP, datacenter, and mobile proxies, providing unmatched geographic targeting and reliability for scraping tasks.
- Web Unlocker: An automated solution designed to manage browser fingerprints, cookies, and CAPTCHAs, significantly increasing the success rate of data extraction from protected websites.
- Web Scraper IDE: A development environment that allows technical users to create, run, and manage large-scale data collectors on Bright Data's infrastructure.
- Pricing: The platform operates on a pay-as-you-go model for its various services (proxies, scrapers, etc.), which can be very powerful but may become expensive. It is best suited for well-funded projects rather than small-scale or hobbyist use.
Key Insight: Bright Data is less of a simple scraping tool and more of a foundational data infrastructure provider. It excels at solving the most difficult part of data extraction: reliably accessing the target web page. For those looking for more direct scraping of specific platforms, you can find a guide for a Google Maps data scraper here.
Website: https://brightdata.com/
8. Diffbot
Diffbot approaches data extraction automation from a fundamentally different angle, positioning itself not just as a scraper but as an AI-powered knowledge engine. Instead of requiring users to specify CSS selectors or page layouts, Diffbot uses advanced computer vision and machine learning models to automatically understand and deconstruct web pages. It identifies elements like articles, products, discussions, and people, then transforms that unstructured HTML into clean, structured JSON data without manual rule-setting.
This AI-driven approach makes it exceptionally powerful for large-scale, heterogeneous data projects where the target websites have inconsistent or frequently changing structures. Diffbot’s core offering is its suite of automatic extraction APIs and its massive "Knowledge Graph," a pre-crawled and interconnected database of billions of entities. This makes it an ideal solution for market intelligence, news monitoring, and building complex datasets where context and relationships between data points are critical.
Core Features & Implementation
- Automatic Extraction APIs: Diffbot offers specific APIs (e.g., Article, Product, Analyze) that automatically parse different page types, converting them into structured data with high accuracy.
- Knowledge Graph: Users can tap into a vast, pre-existing database of organizations, people, and articles, allowing for data enrichment and deeper analysis beyond simple page extraction.
- Computer Vision Technology: Its ability to visually interpret a webpage like a human allows it to bypass the need for traditional scraper maintenance, adapting to layout changes automatically.
- Pricing: Diffbot operates on a custom pricing model, typically targeting enterprise clients. You will need to contact their sales team for a quote, which is based on usage volume and access to features like the Knowledge Graph.
Key Insight: Diffbot is less of a DIY scraping tool and more of an enterprise-grade "data-as-a-service" platform. Its strength is its AI-driven, structure-agnostic extraction, making it perfect for complex projects where maintaining traditional scrapers would be impractical. For straightforward, on-page data collection, a browser-based tool like our Chrome extension can offer a simpler, more direct solution.
Website: https://www.diffbot.com/
9. OutWit Hub
OutWit Hub stands out as a desktop-based web data extraction software that integrates a browser directly into its interface. This unique approach allows users to navigate to a target webpage and then use the tool's built-in functions to automatically identify and pull information. It excels at recognizing common data types like links, images, emails, and documents, as well as finding patterns in structured and unstructured text, making it a versatile tool for quick, on-the-fly extractions without writing any code.

The platform's strength lies in its simplicity and accessibility for non-technical users. Instead of configuring complex bots or APIs, you simply browse and click. OutWit Hub can automatically crawl through a series of links, such as search engine result pages or product listings, and compile the extracted data into a clean, formatted table. This makes it an ideal solution for professionals in marketing, sales, or research who need a straightforward way to build contact lists, gather product details, or compile research materials without a steep learning curve.
Core Features & Implementation
- Integrated Browser: The built-in browser is central to the user experience, allowing you to visually identify the data you want to extract before launching the automated process.
- Automatic Data Recognition: The software is designed to automatically find and grab various data elements, from simple contact info to complex data tables, without manual configuration.
- Structured Export: All extracted data is organized into formatted tables that can be easily exported to formats like spreadsheets (CSV, Excel), SQL, and JSON for further analysis.
- Pricing: OutWit Hub offers a light, free version with basic capabilities. The Pro version is a one-time purchase, providing access to more advanced features like scheduled jobs and deeper scraping functions.
Key Insight: OutWit Hub is a powerful entry-level tool for those who prefer a visual, hands-on approach to data extraction automation. Its strength is in its simplicity, but it may struggle with highly dynamic, JavaScript-heavy websites where cloud-based solutions excel. For simpler browser-based tasks, a tool like our Chrome extension can be a great starting point.
Website: https://outwit.com/
10. Webscraper.io
Webscraper.io offers a highly accessible entry point into the world of data extraction automation, primarily through its popular Chrome extension. It allows users to build "sitemaps" that visually map out how to navigate a website and which data points to extract, making it an excellent tool for those who prefer a point-and-click interface over writing code. This approach is particularly effective for scraping modern, dynamic websites that rely heavily on JavaScript and AJAX to load content.
The platform bridges the gap between simple browser extensions and powerful cloud-based scraping. Users can design and test their scrapers locally for free using the extension and then deploy them to the Webscraper.io cloud for scheduled, large-scale, and parallel scraping tasks. This dual-mode functionality makes it a versatile choice for users who start with small, manual tasks but anticipate needing more robust, automated data extraction capabilities in the future, such as gathering product prices or real estate data.
Core Features & Implementation
- Point-and-Click Sitemap Builder: The core of Webscraper.io is its visual sitemap builder, which lets you define navigation paths, pagination, and data selectors without writing any code. This is ideal for handling complex site structures.
- Dynamic Website Support: It is specifically designed to handle JavaScript and AJAX, allowing it to extract data from interactive elements, pop-ups, and infinitely scrolling pages that simpler tools often miss.
- Cloud-Based Automation: Paid plans unlock cloud scraping, enabling automated, scheduled jobs with IP rotation and scalable infrastructure, removing the need to run scrapes from your own computer.
- Data Export and Integrations: Extracted data can be easily exported to CSV, XLSX, and JSON formats. The platform also offers integrations with Dropbox, Google Sheets, and Amazon S3 for seamless data workflows.
- Pricing: A generous free-forever browser extension is available for local scraping. Paid plans are tiered based on the number of cloud credits, page loads, and features like API access.
Key Insight: Webscraper.io excels at empowering non-technical users to tackle complex scraping jobs. Its visual sitemap approach demystifies the process of data extraction automation for dynamic websites. For those seeking a simpler browser-only solution for static pages, our Chrome extension provides a fast and efficient alternative.
Website: https://webscraper.io/
11. Scrapy
Scrapy is a foundational open-source Python framework built specifically for developers who need to create powerful, fast, and scalable web scraping applications. Unlike GUI-based tools, Scrapy is a code-first environment that provides the underlying engine for building custom crawlers, often called "spiders." Its key differentiator is its asynchronous request handling, which allows it to process multiple pages simultaneously, making it exceptionally efficient for large-scale data extraction automation projects.
This framework is not for beginners or those without programming skills; it has a steep learning curve but offers unparalleled control and performance in return. Developers can precisely define how to find, follow, and parse links, handle cookies and sessions, and process extracted items through a pipeline for cleaning, validation, and storage. Scrapy's robust architecture and extensive documentation make it the go-to choice for complex scraping tasks where pre-built tools are too restrictive or slow.
Core Features & Implementation
- Asynchronous Processing: Built on Twisted, an event-driven networking engine, Scrapy sends requests non-blockingly, leading to very high crawling speeds.
- Extensible Pipeline: It features an "Item Pipeline" that allows developers to chain multiple data processing components together, such as cleaning HTML, validating data integrity, and saving to various databases (e.g., MongoDB, PostgreSQL).
- Middleware Support: Developers can inject custom code to handle requests and responses, enabling advanced functionalities like managing proxies, user agents, and retries.
- Pricing: Scrapy is completely free and open-source. Costs are only associated with the infrastructure (servers, proxies) you use to run your spiders.
Key Insight: Scrapy is the engine, not the car. It provides the power and components for sophisticated data extraction automation but requires significant developer effort to build and maintain. For those who need a browser-based, no-code alternative for simpler tasks, you can download our Chrome extension to deliver results much faster.
Website: https://scrapy.org/
Key Features Comparison of Top 11 Data Extraction Tools
| Product | Core Features / Capabilities | User Experience / Quality ★★★★☆ | Value & Pricing 💰 | Target Audience 👥 | Unique Selling Points / Highlights ✨🏆 |
|---|---|---|---|---|---|
| 🏆 PandaExtract - Ultimate Web Scraper | No-code hover-click scraping, bulk URL extraction, email & image harvesting, cloud scheduling | Intuitive no-code UI, built-in data editor ★★★★☆ | Affordable, no coding needed 💰 | Marketers, researchers, e-commerce pros 👥 | Intelligent selection tool, advanced workflows, seamless exports ✨🏆 |
| Apify | 2,000+ scrapers, headless browser, REST API | Developer-friendly, scalable ★★★★ | Higher pricing for heavy use 💰 | Developers, enterprises 👥 | Massive scraper marketplace, API integrations ✨ |
| Octoparse | Visual workflow, IP rotation, cloud/local scrape | Easy drag-drop UI, handles dynamic websites ★★★★☆ | Free & paid plans 💰 | Non-technical users, SMBs 👥 | CAPTCHA solving, pre-built templates ✨ |
| ParseHub | Dynamic content, desktop & cloud, conditional logic | Point-and-click, effective on complex sites ★★★★ | Free tier available 💰 | Non-programmers, small projects 👥 | Cloud + desktop flexibility, Dropbox integration ✨ |
| Nanonets | AI & OCR-powered data extraction, no-code workflows | High accuracy, user-friendly ★★★★☆ | Premium pricing 💰 | Enterprises, document-heavy users 👥 | AI-adaptive models, CRM exports ✨ |
| Hevo Data | 150+ data sources, real-time replication | Reliable, easy setup ★★★★ | Expensive for startups 💰 | Data engineers, businesses 👥 | Fault tolerance, automated schema mapping ✨ |
| Bright Data | Proxy networks, web scraper IDE, CAPTCHA bypass | High success rate, scalable ★★★★☆ | Premium pricing 💰 | Large-scale enterprises 👥 | Proxy coverage, Web Unlocker tech ✨ |
| Diffbot | ML + computer vision extraction, knowledge graphs | Accurate, advanced data analysis ★★★★ | Pricing not public 💰 | Data scientists, enterprises 👥 | Billion-entity knowledge graph, automation APIs ✨ |
| OutWit Hub | Built-in browser, structured & unstructured data | User-friendly but basic features ★★★ | Affordable 💰 | Casual & non-technical users 👥 | Automatic link/image extraction, easy exports ✨ |
| Webscraper.io | Dynamic site scraping, AJAX/JS support, sitemap editor | Easy extension, effective scraping ★★★★ | Free + paid plans 💰 | SMBs, non-developers 👥 | Cloud version, integrations w/ Dropbox & Sheets ✨ |
| Scrapy | Open-source Python framework, asynchronous scraping | Highly efficient but coding required ★★★★☆ | Free and open-source 💰 | Developers, data engineers 👥 | Extensively customizable, large community support ✨ |
Making Your Choice: From Simple Clicks to Complex Code
We've journeyed through the diverse landscape of data extraction automation, exploring a spectrum of tools designed for vastly different needs, skill levels, and project scopes. From the developer-centric power of Scrapy to the enterprise-scale infrastructure of Bright Data and the visual workflow builders like Octoparse, one truth is clear: the right tool is the one that aligns with your specific objectives. The goal is no longer just about accessing data, but about integrating it seamlessly into your decision-making processes.
The central challenge is to match the tool to the task. A complex, code-heavy framework is overkill for a market researcher who simply needs to pull product pricing from a handful of competitor sites. Conversely, a simple browser extension may not suffice for an enterprise-level project requiring millions of data points with robust anti-bot measures. This article has aimed to provide a clear map, helping you navigate from simple clicks to complex code.
Key Takeaways and Decision Factors
Your choice hinges on a balance of technical expertise, project scale, budget, and the specific type of data you need. To distill our findings, consider these pivotal factors before making a commitment:
- Technical Skill Level: This is the most critical starting point. Are you a non-technical professional who needs results now, or a developer comfortable with Python? For the former, tools like PandaExtract, ParseHub, and Octoparse offer no-code or low-code environments. For the latter, frameworks like Scrapy or platforms like Apify provide unparalleled flexibility and power.
- Project Scale and Frequency: Are you conducting a one-off data pull or setting up a continuous monitoring system? For quick, ad-hoc tasks, a browser extension is incredibly efficient. For large-scale, recurring jobs that run daily or hourly, you need a more robust solution like Hevo Data or Bright Data's platform, which can handle scheduling, proxy management, and data warehousing.
- Target Website Complexity: The structure of your target websites dictates the necessary features. Modern, dynamic sites built with JavaScript frameworks often break simpler scrapers. Tools like PandaExtract, Diffbot, and Apify are specifically engineered to handle these complexities, executing JavaScript to render pages just as a human user would, ensuring you capture all the data.
- Budget and Total Cost of Ownership: The price tag isn't the only cost. Consider the time investment required for setup, training, and maintenance. While a "free" tool like Scrapy has no upfront cost, it demands significant development and infrastructure management time. Subscription-based platforms bundle these costs into a predictable monthly fee, which can be more economical when you factor in team resources.
Your Actionable Next Steps
The journey into data extraction automation begins with a single, practical step. Don't get paralyzed by the sheer number of options. Instead, start small and build momentum.
First, identify your most immediate and high-value use case. Is it lead generation, competitor price monitoring, or sentiment analysis? Pinpointing a clear, tangible goal will instantly narrow your choices.
Second, be honest about your team's technical comfort level. Choosing a tool that requires skills your team doesn't possess will only lead to frustration and abandonment. The best tool is one that gets used.
Finally, start with a trial or a free version. Nearly every tool on our list, from Webscraper.io to Nanonets, offers a way to test its capabilities. For immediate needs, installing a browser extension is the lowest-friction path to experiencing the power of automation firsthand. This hands-on experience is invaluable for understanding how a tool truly fits into your workflow.
The era of manual data collection is over. The competitive advantage now belongs to those who can efficiently harness automated systems to gather, process, and analyze information at scale. By carefully selecting the right tool, you empower yourself and your team to move beyond tedious data entry and focus on what truly drives growth: strategic, data-informed action.
Ready to stop copying and pasting and start automating? The fastest way to experience the benefits of data extraction automation is with a tool you can use today. Install the PandaExtract - Ultimate Web Scraper Chrome extension and begin pulling structured data from any website in minutes, no coding required. Get started for free on our website.
Published on