12 Best Web Site Data Extractor Tools for 2025

In today's data-driven world, the ability to efficiently gather information from the web is a superpower. Whether you're a market researcher tracking competitor pricing, a journalist compiling data for a story, or a sales professional building lead lists, a powerful web site data extractor is indispensable. But the market is crowded with options, ranging from simple browser extensions to enterprise-level platforms. How do you choose the right one?
This guide cuts through the noise. We provide a detailed comparison of the 12 leading web site data extractor tools, complete with screenshots and direct links. For each tool, we analyze its real-world performance, ideal use cases, and honest limitations, so you can make an informed decision. Beyond general web data extraction, e-commerce professionals often utilize specialized 12 Best Tools for Amazon FBA Sellers to streamline their operations and gain market intelligence.
Our goal is simple: to help you find the best platform for your specific needs. We'll examine everything from user interface and learning curve to handling dynamic content and pricing models. By the end, you'll have a clear understanding of which tool will help you turn web pages into actionable insights without the technical headache. For a quick start, you can also download our own robust Chrome extension, the Ultimate Web Scraper, and begin extracting data in minutes.
1. PandaExtract - Ultimate Web Scraper: The All-in-One No-Code Solution
PandaExtract establishes itself as a premier web site data extractor, specifically engineered for professionals who require fast, reliable, and structured data without writing a single line of code. Its core distinction lies in a remarkably intuitive hover-and-click interface, which effectively democratizes the data extraction process. This approach allows users, regardless of technical skill, to effortlessly capture complex data structures from any website.
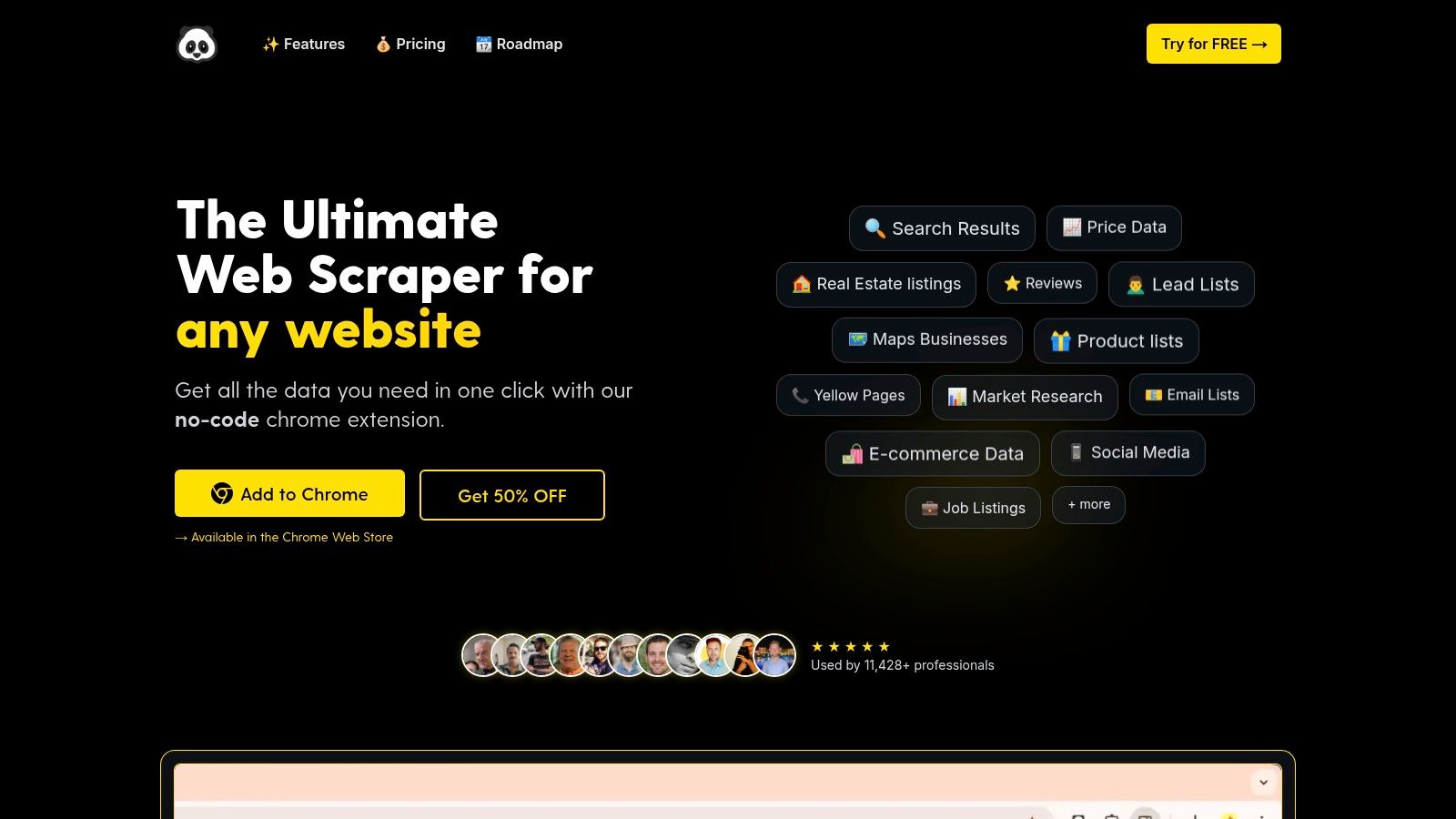
As the broader 'no-code' movement continues to empower users to build and manage web assets without extensive coding, including powerful no-code web development solutions, web data extractors like PandaExtract are making data collection equally accessible. This tool is a powerhouse for serious data gathering tasks, trusted by over 11,400 users for harvesting insights from platforms like Shopify, Amazon, Zillow, and Google Maps.
Key Strengths and Use Cases
PandaExtract excels with its robust feature set designed for real-world applications. The intelligent selection tool automatically identifies lists, tables, and paginated content, drastically reducing setup time.
- Lead Generation: Sales and marketing teams can bulk-upload a list of company websites from a CSV file and use the deep subpage scanning feature to automatically find and extract contact emails and phone numbers from their "Contact Us" or "About Us" pages.
- Market Research: E-commerce managers can quickly scrape product details, pricing, and customer reviews from competitor sites like Amazon or Shopify to perform competitive analysis.
- Data Aggregation: Analysts can extract real estate listings from Zillow or business details from Google Maps, complete with paginated results, and then organize the data directly within the integrated spreadsheet editor before exporting to Google Sheets for further analysis.
"The built-in spreadsheet editor is a significant advantage, allowing for on-the-fly data cleaning and organization before export. For those seeking maximum efficiency, PandaExtract is a top contender."
Implementation and User Experience
Getting started is straightforward. As a browser extension for Chrome, Edge, and Brave, installation is a one-click process. Once installed, users navigate to the target website, activate the extension, and begin selecting the data they need. The interface is clean and responsive, making it one of the most user-friendly data extraction tools available. Download the Chrome extension to try it now.
Pros and Cons
Pros:
- No-Code Interface: Its hover-and-click system makes data extraction incredibly simple.
- Bulk & Deep Scanning: Supports multi-page and deep subpage scanning with bulk URL uploads for large-scale projects.
- Diverse Data Extraction: Captures lists, tables, emails, images with filters, and clean text with metadata.
- Built-in Editor: Allows for filtering, editing, and organizing data before exporting to CSV, Excel, or Google Sheets.
- Highly Trusted: Strong positive user reviews praise its speed, accuracy, and flexibility.
Cons:
- Browser Limitation: Currently available only as a Chrome, Edge, and Brave extension.
- Upcoming Features: Some advanced capabilities like recurring jobs and cloud scheduling are not yet fully available.
Access the Tool:
- Download the PandaExtract Chrome Extension
- Learn more about its capabilities as a website data scraper
- Website: https://pandaextract.com
2. Import.io
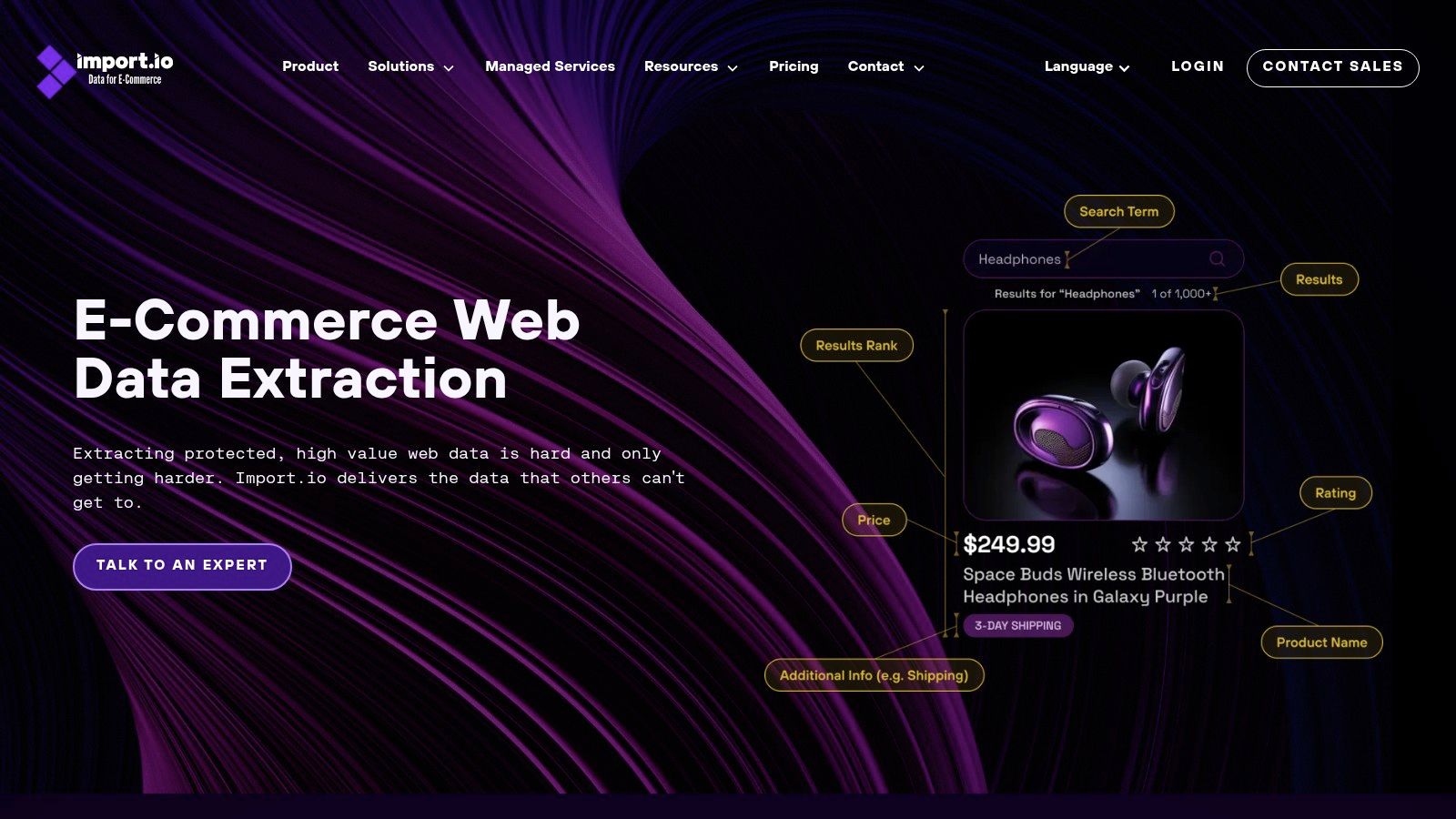
Import.io is a powerful, enterprise-focused web site data extractor designed for users who need structured data without writing any code. Its core strength lies in its intuitive, point-and-click interface that transforms complex websites into organized datasets. This makes it an excellent choice for business analysts, marketing teams, and e-commerce managers who need to gather competitive intelligence or market data at scale but lack dedicated development resources.
The platform stands out by automating much of the extraction process. Users can simply highlight the data fields they want, and Import.io's engine learns the page structure to replicate the extraction across similar pages. This no-code approach significantly lowers the barrier to entry for large-scale data projects.
Key Features & Use Cases
- User Experience: The UI is clean and guides users through creating an "extractor" (a scraping recipe). The visual selector tool is particularly effective for targeting specific data points on a page.
- Integration: It offers robust integration capabilities, allowing you to feed extracted data directly into CRMs like Salesforce, business intelligence tools like Tableau, or other third-party applications via its API.
- Automation: You can schedule extractions to run automatically, ensuring your datasets are always up-to-date with the latest information from the target websites. This is ideal for price monitoring or tracking new product listings.
- Data Formats: Data can be downloaded in multiple formats, including CSV, JSON, and XML, providing flexibility for analysis.
| Feature | Details |
|---|---|
| Ideal User | Business professionals, market researchers, and teams without coding skills. |
| Pricing | Enterprise-level, custom pricing. Generally considered a premium solution. |
| Key Differentiator | Point-and-click simplicity combined with enterprise-grade scale and support. |
| Website | https://www.import.io/ |
Pros and Cons
Pros:
- No Coding Required: Its point-and-click interface is one of the most user-friendly on the market.
- Scalability: Built to handle large-scale, ongoing data extraction projects for business intelligence.
- Seamless Integrations: Strong API and native integrations simplify data workflows.
Cons:
- Cost: The pricing model is geared toward enterprises and can be prohibitive for small businesses or individual users.
- Dynamic Websites: It can sometimes struggle with websites that rely heavily on JavaScript to load content, requiring more manual configuration.
3. Octoparse
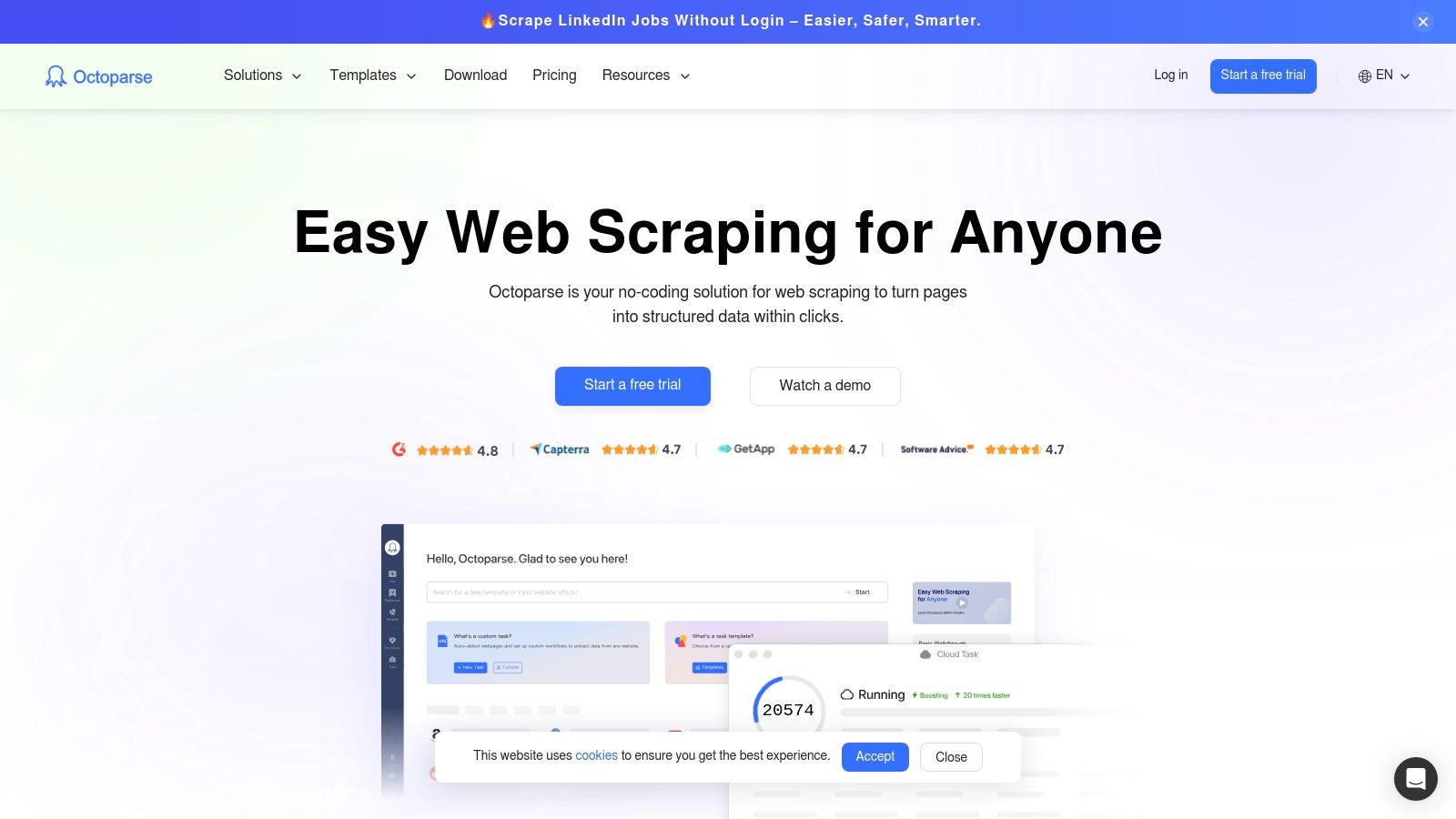
Octoparse is a powerful, client-based web site data extractor that empowers non-coders to pull information from both simple and complex websites. It bridges the gap between basic browser extensions and enterprise-level platforms by offering a visual workflow builder that mimics human interaction, such as clicking buttons, entering text, and scrolling through pages. This makes it a versatile choice for users who need to handle dynamic content loaded with JavaScript or navigate login forms without writing any code.
The platform's strength lies in its flexibility, offering both local extraction on your own machine and cloud-based extraction for large-scale, automated tasks. Its use of pre-built templates for popular sites like Amazon and Yelp also provides a significant head start for common data gathering projects, lowering the initial learning curve. For more straightforward tasks, a simple browser extension like the Ultimate Web Scraper can be a quicker alternative. Download the Chrome Extension here.
Key Features & Use Cases
- User Experience: The point-and-click interface and visual workflow designer simplify the process of creating a scraper. While powerful, it requires some initial learning to master advanced scraping logic.
- Automation: Cloud extraction allows for scheduled scraping jobs that run 24/7, with automatic IP rotation to minimize the risk of being blocked by target websites.
- Dynamic Websites: It excels at handling sites that rely on AJAX, JavaScript, and infinite scroll, which are often challenging for simpler tools.
- Templates: A library of pre-built templates for e-commerce, social media, and business directory sites accelerates the data collection process for beginners.
| Feature | Details |
|---|---|
| Ideal User | Marketers, e-commerce managers, and data analysts needing a robust no-code tool. |
| Pricing | Offers a free plan with limitations; paid plans are tiered for more features. |
| Key Differentiator | Advanced handling of dynamic websites and a hybrid local/cloud extraction model. |
| Website | https://www.octoparse.com/ |
Pros and Cons
Pros:
- Handles Complexity: Effectively scrapes dynamic websites that other tools struggle with.
- Flexible Deployment: Users can choose between running tasks locally for free or using the scalable cloud service.
- User-Friendly: The visual designer is intuitive for creating scrapers without any programming knowledge.
Cons:
- Learning Curve: Mastering its more advanced features, like XPath modification and loop configurations, can take time.
- Resource Intensive: The desktop application can be heavy on local machine resources, especially for complex tasks.
4. ParseHub
ParseHub is a powerful web site data extractor that operates as a desktop application, offering a visual, no-code interface for scraping complex websites. Its primary strength is its ability to handle dynamic content, including sites that rely heavily on JavaScript, AJAX, forms, and infinite scroll. This makes it an excellent choice for users who need to extract data from interactive web applications but prefer an installable tool over a cloud-based platform.
The platform distinguishes itself by combining the ease of a point-and-click interface with advanced scraping capabilities typically found in code-based solutions. Users can train ParseHub to navigate through logins, fill out forms, and handle complex page structures, all within its intuitive desktop client. For users looking for a lightweight, browser-based alternative for simpler tasks, our Ultimate Web Scraper Chrome extension is a great starting point. Download the extension here to get started quickly.
Key Features & Use Cases
- User Experience: The desktop UI allows users to click on elements to select data, with a clear workflow for building scraping "projects" that can handle complex logic like loops and conditional actions.
- Dynamic Content: It excels at scraping data from single-page applications (SPAs) and sites with interactive maps or forms, which many simpler tools cannot handle.
- Automation & Integration: Projects run on ParseHub's servers, and you can schedule them to run automatically. Paid plans offer API access for integrating the extracted data into other systems.
- Data Formats: You can export collected data as CSV, JSON, or Excel files, making it compatible with most data analysis workflows.
| Feature | Details |
|---|---|
| Ideal User | Researchers, analysts, and developers needing to scrape complex, dynamic sites. |
| Pricing | Freemium model with a generous free plan; paid plans add features and scale. |
| Key Differentiator | Robust handling of JavaScript-heavy websites in a desktop application format. |
| Website | https://www.parsehub.com/ |
Pros and Cons
Pros:
- Handles Complexity: One of the best no-code tools for scraping websites with infinite scroll, logins, and dropdowns.
- Generous Free Plan: The free tier is quite capable for small projects, making it accessible for individuals and startups.
- No Coding Required: Its visual interface allows non-developers to build powerful scrapers.
Cons:
- Desktop-Only: Being a desktop application can be a limitation for users who prefer a fully web-based workflow or need to work across different machines.
- Speed Limitations: The free plan has speed and page-per-run limits (200 pages), which can be restrictive for large-scale jobs.
5. Apify
Apify is a unique web site data extractor that functions as a flexible cloud platform for web scraping and automation. It caters to a more technical audience, bridging the gap between no-code tools and entirely custom-built solutions. Its primary strength is the Apify Store, a marketplace full of pre-built scrapers ("Actors") for common targets like social media, e-commerce sites, and Google Maps.
This platform empowers developers and data scientists to build, run, and scale their own scraping tools in a serverless environment. For those without the time or expertise to build from scratch, the ready-made Actors provide a powerful head start, making complex data extraction projects more accessible. Learn more about Apify and similar web scraping tools to find the perfect fit for your needs.
Key Features & Use Cases
- Apify Store: Access a wide variety of pre-built scrapers for nearly any task, from extracting real estate listings to monitoring social media trends.
- Custom Development: Provides a robust environment with SDKs for Node.js and Python, allowing developers to build highly specific and complex scrapers.
- Cloud-Based & Scalable: All operations run in the cloud, handling everything from proxy management to parallel execution, ensuring your projects can scale on demand.
- Robust Integration: Features a powerful API, webhooks, and integrations to connect your extracted data with other systems and applications.
| Feature | Details |
|---|---|
| Ideal User | Developers, data scientists, and technical users needing custom solutions. |
| Pricing | Offers a free tier, with paid plans based on usage and compute units. |
| Key Differentiator | A hybrid platform combining a marketplace of tools with a custom dev environment. |
| Website | https://apify.com/ |
Pros and Cons
Pros:
- Ultimate Flexibility: You can use pre-built tools, modify them, or build entirely new ones from scratch.
- Handles Complexity: Excellent for scraping dynamic, JavaScript-heavy websites that challenge simpler tools.
- Strong Community: An active user base and marketplace provide great support and ready-to-use solutions.
Cons:
- Learning Curve: Requires some technical or coding knowledge to leverage its full capabilities.
- Usage-Based Costs: Large-scale or inefficiently coded scrapers can become expensive due to the pricing model.
6. ScraperAPI
ScraperAPI is a specialized tool for developers who need a reliable web site data extractor but want to avoid the complexities of managing proxies and bypassing anti-bot measures. Instead of providing a user interface for scraping, it offers a simple API that handles all the technical hurdles. You send a request with the target URL, and ScraperAPI returns the raw HTML, allowing developers to focus solely on parsing the data.
This approach makes it ideal for integrating data extraction into custom applications or for large-scale projects where avoiding blocks and CAPTCHAs is critical. By managing a pool of millions of proxies, rendering JavaScript, and solving CAPTCHAs automatically, it ensures a high success rate for requests.
Key Features & Use Cases
- Proxy Management: Automatically rotates through millions of proxies across dozens of ISPs, including residential and mobile IPs, to prevent IP bans.
- Anti-Bot Bypassing: It is built to handle CAPTCHAs and browser fingerprinting, ensuring consistent access to even the most challenging websites.
- JavaScript Rendering: Capable of rendering pages with JavaScript, allowing you to scrape dynamic content from modern web applications.
- Geotargeting: You can make requests from specific geographic locations, which is essential for scraping localized content like pricing or search results.
| Feature | Details |
|---|---|
| Ideal User | Developers and data engineers building custom scraping applications. |
| Pricing | Tiered plans based on API credits, with a free tier for small projects. |
| Key Differentiator | A simple API that abstracts away the most difficult parts of web scraping. |
| Website | https://www.scraperapi.com/ |
Pros and Cons
Pros:
- High Success Rates: Effectively manages proxies and anti-bot systems, leading to reliable data retrieval.
- Easy Integration: Simple to add to any project using any programming language that can make an HTTP request.
- Scalability: Built to handle millions of requests, making it suitable for large-scale, ongoing projects.
Cons:
- Requires Coding Knowledge: It is not a no-code tool; you must write your own parser to extract data from the returned HTML.
- Usage-Based Cost: Can become expensive for very high-volume scraping, as pricing is tied to the number of successful API calls.
7. Oxylabs
Oxylabs is a premium web site data extractor solution focused on providing robust, large-scale data gathering infrastructure. Rather than a point-and-click tool, it offers a suite of powerful Scraper APIs and one of the largest proxy networks in the world. This makes it the go-to choice for enterprises and data scientists who need reliable, high-volume data extraction while managing complex challenges like IP blocks, CAPTCHAs, and geographic restrictions.
The platform's core strength is its infrastructure-as-a-service model. It handles the difficult backend of web scraping, allowing developers to focus on data utilization. Oxylabs is built for performance and reliability, ensuring that data pipelines for market research, price monitoring, or SERP analysis remain stable and consistent.
Key Features & Use Cases
- Proxy Infrastructure: Provides access to a massive, ethically sourced proxy pool, including residential and datacenter IPs, which is essential for avoiding detection and accessing geo-specific content.
- Scraper APIs: Offers specialized APIs for various targets like e-commerce, search engines, and general websites. These APIs deliver structured JSON data, saving significant development time.
- CAPTCHA & Block Handling: The system automatically handles complex anti-bot measures, ensuring a high success rate for data requests without manual intervention.
- Data Quality: Known for delivering clean and accurate data, which is critical for business intelligence and machine learning applications.
| Feature | Details |
|---|---|
| Ideal User | Enterprises, data scientists, and developers needing a reliable data infrastructure. |
| Pricing | Pay-as-you-go and subscription plans; considered a premium-priced service. |
| Key Differentiator | Unmatched proxy network size and reliability for large-scale, resilient scraping. |
| Website | https://oxylabs.io/ |
Pros and Cons
Pros:
- High Reliability: Exceptional uptime and success rates, even with difficult target sites.
- Scalability: Built to handle millions of data requests for the most demanding projects.
- Ethical Sourcing: Emphasizes ethical practices in its proxy acquisition and usage.
Cons:
- Developer-Focused: Requires coding knowledge to integrate with its APIs; not suitable for non-technical users.
- Cost: Pricing can be high for small-scale projects or individual developers.
8. Web Scraper
Web Scraper is a highly accessible web site data extractor that operates as a browser extension, bringing data extraction capabilities directly into your workflow. Its primary advantage is simplicity, allowing users to build scraping "sitemaps" that navigate a website and pull specific data without writing a single line of code. This makes it an excellent entry point for individuals, students, and small businesses looking to automate data gathering for market research or lead generation.
The tool works by letting you point and click on the elements you want to extract, such as product names, prices, or contact details. It’s particularly adept at handling modern web features, including pagination, infinite scroll, and content loaded via JavaScript, which are common hurdles for simpler scrapers.
Key Features & Use Cases
- User Experience: The interface is built directly into the browser’s developer tools, which may be unfamiliar at first but becomes intuitive once you learn the sitemap-building process.
- Dynamic Content: It has strong support for scraping data from dynamic pages that rely on JavaScript, a key feature not always found in free browser-based tools.
- Cloud Integration: For larger projects, Web Scraper offers a cloud service that can run scrapers, manage proxies, and store data, transforming the simple extension into a more robust solution.
- Data Formats: Data can be easily exported in CSV, XLSX, and JSON formats, making it compatible with most data analysis software.
| Feature | Details |
|---|---|
| Ideal User | Beginners, students, marketers, and users needing a free or low-cost scraping solution. |
| Pricing | The browser extension is free. Paid plans are available for cloud services and API access. |
| Key Differentiator | A powerful free-tier browser extension with an optional, scalable cloud platform. |
| Website | https://webscraper.io/ |
Pros and Cons
Pros:
- No Coding Required: The point-and-click interface is easy for non-programmers to master.
- Free and Accessible: The core functionality is available for free through its Chrome extension.
- Handles Complex Sites: Effectively scrapes JavaScript-rendered content, pagination, and various site structures.
Cons:
- Learning Curve: The sitemap-building logic can take some time to get used to.
- Cloud Services Cost: Large-scale and automated scraping requires a paid subscription to its cloud platform.
9. ScrapingBee
ScrapingBee is a developer-focused API designed to simplify the complexities of web scraping. Instead of providing a user interface, it offers a powerful backend service that handles headless browsers, proxy rotation, and CAPTCHA solving. This makes it an ideal web site data extractor for developers who want to avoid getting blocked and manage JavaScript-heavy websites without building and maintaining their own complex infrastructure.
The platform’s core value lies in its reliability and ease of integration. By sending a simple API call, developers can render any web page just as a real browser would, ensuring all dynamically loaded content is captured. This approach is perfect for projects requiring high success rates, such as price monitoring, lead generation, or gathering data from single-page applications.
Key Features & Use Cases
- Headless Browser Management: It uses the latest Chrome versions to render pages, executing JavaScript to access content that traditional scrapers miss.
- Automatic Proxy Rotation: All requests are routed through a massive proxy pool, with options for residential and premium proxies to significantly reduce the chance of being blocked. This is crucial when you scrape ecommerce data.
- Geotargeting: You can make requests from specific countries, which is essential for scraping localized content like pricing or search results.
- Custom Logic: Users can execute custom JavaScript snippets on the target page to perform actions like clicking buttons or scrolling before the HTML is returned. For those who prefer a non-API solution, our Chrome extension offers a codeless alternative.
| Feature | Details |
|---|---|
| Ideal User | Developers and data teams who need a reliable scraping API. |
| Pricing | Usage-based, with plans starting from a free tier. |
| Key Differentiator | An all-in-one API that handles proxies, browsers, and CAPTCHAs. |
| Website | https://www.scrapingbee.com/ |
Pros and Cons
Pros:
- High Success Rates: Effectively bypasses many anti-scraping measures.
- Language Agnostic: Works with any programming language that can make an HTTP request.
- Scalable: Designed to handle a large volume of requests for big data projects.
Cons:
- Requires Coding Knowledge: It is an API, not a point-and-click tool, so it’s unsuitable for non-developers.
- Potential Cost: The pay-as-you-go model can become expensive for very large-scale or inefficient scraping jobs.
10. Diffbot
Diffbot is an advanced web site data extractor that uses AI and machine learning to automatically convert the unstructured web into structured, meaningful data. Instead of requiring users to manually select elements, Diffbot's APIs can identify and extract specific content types like articles, products, or discussions from any URL, returning clean, organized JSON. This makes it a go-to solution for enterprises that need comprehensive, machine-readable data at a massive scale.
The platform excels at understanding the context of a webpage, not just its visual layout. This AI-driven approach allows it to handle complex, dynamic sites and extract nuanced information with high accuracy, making it a powerful tool for developers and data scientists building sophisticated applications.
Key Features & Use Cases
- Automatic Extraction: Its AI-powered APIs automatically identify and parse articles, products, images, and other common page types without manual setup or training.
- Knowledge Graph: Diffbot's standout feature is its Knowledge Graph, a massive, interconnected database of entities from across the web, ideal for market intelligence and machine learning.
- Dynamic Content: It is highly effective at crawling and parsing websites that rely heavily on JavaScript and AJAX to load content.
- Multilingual Support: The platform can process and understand content in multiple languages, making it suitable for global data collection projects.
| Feature | Details |
|---|---|
| Ideal User | Developers, data scientists, and enterprises needing large-scale, automated data extraction. |
| Pricing | Offers a free trial, with paid plans based on API call volume. Can be costly for heavy use. |
| Key Differentiator | AI-based automatic data recognition and its massive, pre-built Knowledge Graph. |
| Website | https://www.diffbot.com/ |
Pros and Cons
Pros:
- Highly Automated: Eliminates the need for manual scraper configuration on most websites.
- Comprehensive Data: Can extract rich, contextual data beyond simple text fields.
- Scalable: Built to handle millions of pages, making it ideal for enterprise-level projects.
Cons:
- Requires Technical Skill: It's an API-first product, requiring development knowledge to integrate and use effectively.
- Cost: Pricing can become a significant expense for projects requiring extensive API calls.
11. Content Grabber
Content Grabber is a powerful desktop-based web site data extractor designed for users who need deep control over complex scraping projects. It combines a visual, point-and-click editor with robust scripting capabilities, making it suitable for both non-technical users and developers. This hybrid approach allows businesses to tackle challenging data extraction from dynamic websites, including those with AJAX, CAPTCHAs, and complex pagination.
The software runs on Windows and is engineered for enterprise-level tasks that require reliability and scalability. It excels at managing large, automated scraping agents that can be scheduled to run periodically, ensuring data for competitive analysis or market research is consistently fresh. Its strength lies in handling intricate scenarios that simpler cloud-based tools might fail to navigate.
Key Features & Use Cases
- User Experience: Features a visual editor that looks and feels like a web browser, allowing users to build scraping agents by simply clicking on the elements they wish to extract.
- Dynamic Content: It has built-in capabilities to handle dynamic websites, interact with forms, manage logins, and process websites that heavily rely on JavaScript.
- Automation: Offers powerful scheduling and automation features, including command-line control and an API for integration into larger enterprise workflows.
- Data Formats: Extracted data can be exported to a wide variety of formats, including CSV, Excel, XML, and directly to databases like SQL Server, MySQL, and Oracle.
| Feature | Details |
|---|---|
| Ideal User | Businesses, data analysts, and developers needing a robust solution for complex scraping. |
| Pricing | Premium, with various licensing options available based on features and scale. |
| Key Differentiator | A powerful blend of a visual editor with advanced scripting and debugging capabilities. |
| Website | https://contentgrabber.com/ |
Pros and Cons
Pros:
- Highly Powerful: Capable of handling almost any scraping scenario, no matter how complex.
- Visual Interface: The point-and-click editor simplifies the creation of extraction agents.
- Scalable: Designed for large-scale, mission-critical data extraction projects.
Cons:
- Windows-Only: The software requires installation on a Windows operating system, limiting accessibility for Mac and Linux users.
- Cost: It is a premium tool, and its price point may be too high for freelancers or small businesses.
12. OutWit Hub
OutWit Hub is a versatile web site data extractor that operates as a downloadable software application with a built-in browser. It automatically identifies and organizes various types of information from web pages, including links, images, documents, and contact details, without requiring users to write code. This approach makes it a solid choice for individuals and small teams on Windows, macOS, or Linux who need a self-contained tool for ad-hoc data collection.
The software stands out by packaging browsing and extraction into a single interface. Users navigate to a target website within the application, and OutWit Hub automatically parses the content into structured formats. This makes it particularly useful for quickly gathering lists of resources, compiling image galleries, or collecting contact information from online directories.

Key Features & Use Cases
- User Experience: The interface, while functional, can feel somewhat dated compared to modern cloud-based tools. However, its strength lies in its all-in-one browser-extractor design.
- Automation: It includes features for automating the navigation through a series of pages, making it suitable for extracting data from simple paginated lists or search results.
- Data Recognition: The tool automatically recognizes common data types like email addresses, phone numbers, and RSS feeds, simplifying the collection of lead generation or contact data.
- Data Formats: Extracted data can be easily exported to formats like CSV, HTML, or plain text for use in spreadsheets or databases. For a browser-based alternative, you can also download our Ultimate Web Scraper Chrome Extension.
| Feature | Details |
|---|---|
| Ideal User | Individual researchers, marketers, and small business users needing a desktop tool. |
| Pricing | Offers a free light version and paid Pro/Enterprise editions with a one-time fee. |
| Key Differentiator | A self-contained desktop application with automatic data recognition features. |
| Website | https://outwit.com/ |
Pros and Cons
Pros:
- No Coding Required: It is accessible to non-technical users through its integrated browser.
- Cross-Platform: Works on Windows, macOS, and Linux, offering great flexibility.
- Handles Various Data Types: Automatically identifies and extracts links, images, documents, and more.
Cons:
- Outdated Interface: The UI may not feel as intuitive or modern as some web-based competitors.
- Complex Extractions: Can require significant manual setup for websites with complex JavaScript or nested data structures.
Top 12 Web Data Extractors Comparison
| Product | Core Features & Capabilities | User Experience & Quality | Value & Pricing | Target Audience | Unique Selling Points |
|---|---|---|---|---|---|
| 🏆 PandaExtract - Ultimate Web Scraper | No-code, hover-click, multi-page & deep scanning, email & image extraction, built-in spreadsheet editor | ★★★★☆ Intuitive, fast, accurate | 💰 50% off, great value | 👥 Market researchers, marketers, e-commerce, analysts | ✨ No coding, cloud scheduling (soon), n8n/webhooks integration |
| Import.io | Point-&-click, integrates with analytics & CRMs, CSV/JSON/XML, automated refresh | ★★★☆☆ User-friendly | 💰 Pricing high for large scale | 👥 Businesses needing integrations | ✨ Seamless business tool integration |
| Octoparse | Visual workflows, pre-built templates, cloud scheduling, IP rotation | ★★★★☆ Handles AJAX/JS dynamic sites | 💰 Free plan limited | 👥 Users needing local & cloud scraping | ✨ IP rotation, cloud + local mode |
| ParseHub | Desktop app, dynamic content & forms, API access, multiple exports | ★★★☆☆ Decent UX, free version | 💰 Free limited runs | 👥 Users preferring offline scraping | ✨ Supports complex sites, form handling |
| Apify | Marketplace scrapers, custom dev, cloud execution, multi-language integration | ★★★★☆ Flexible & scalable | 💰 Pricing tiered, can be high | 👥 Technical users & developers | ✨ Custom scraper dev & marketplace |
| ScraperAPI | Proxy rotation, CAPTCHA handling, JS rendering, geo-targeting | ★★★★☆ High success, scalable | 💰 Usage-based, can be costly | 👥 Developers needing scalable scraping | ✨ Manages proxies & bot protection |
| Oxylabs | Large proxy pool, geo-restriction & CAPTCHA handling, JSON output | ★★★★☆ Reliable & ethical | 💰 Premium pricing, free trial | 👥 Enterprises & large projects | ✨ Ethical scraping, large proxy pool |
| Web Scraper | Browser extension, dynamic content support, cloud extraction, CSV/XLSX/JSON export | ★★★☆☆ Easy & code-free | 💰 Free extension, subscription for cloud | 👥 Casual to intermediate users | ✨ Free browser extension + cloud |
| ScrapingBee | Headless browsers, proxy rotation, JS rendering, geotargeting | ★★★★☆ High success, scalable | 💰 Usage based, potentially costly | 👥 Developers & tech teams | ✨ Managed headless browsers & proxies |
| Diffbot | Auto-structured data extraction, multi-language, APIs, dynamic content | ★★★★☆ Comprehensive, scalable | 💰 Premium pricing | 👥 Enterprises needing rich data | ✨ AI-powered structured extraction |
| Content Grabber | Visual editor, dynamic content, automation, scheduling | ★★★★☆ Powerful & scalable | 💰 Higher cost, Windows only | 👥 Enterprises, complex projects | ✨ Automation & scheduling |
| OutWit Hub | Built-in browser, multi-OS, exports to sheets/databases | ★★★☆☆ No coding, multi-OS | 💰 Affordable/free tier | 👥 Non-coders across OS platforms | ✨ Built-in browser + multi-OS support |
Final Thoughts: Turn Data into Your Competitive Advantage
The journey through the landscape of modern web site data extractor tools reveals a powerful truth: the ability to programmatically gather and structure information from the internet is no longer a niche skill reserved for developers. It has become a fundamental business capability. We've explored a diverse array of solutions, from the accessible, browser-based PandaExtract - Ultimate Web Scraper and Web Scraper extension to the enterprise-grade power of platforms like Import.io and the developer-centric APIs offered by ScraperAPI and Oxylabs.
Your choice of a web site data extractor is not just a technical decision; it's a strategic one. The right tool acts as a multiplier for your efforts, transforming the chaotic, unstructured web into a clean, organized, and actionable dataset. This empowers market researchers to track competitor pricing in real-time, helps lead generation specialists build highly targeted prospect lists, and allows e-commerce managers to monitor product availability and customer reviews at scale.
How to Choose Your Ideal Web Site Data Extractor
Selecting the perfect tool from this comprehensive list hinges on a clear understanding of your specific needs. To make the best decision, consider these critical factors:
- Technical Proficiency: Are you a non-technical user who needs a point-and-click interface, or a seasoned developer comfortable with APIs and custom scripts? Tools like Octoparse and ParseHub offer a middle ground with visual workflows, while Apify and ScrapingBee cater directly to coders.
- Project Scale and Complexity: Are you performing a one-off extraction from a single page, or do you need to scrape thousands of pages daily from complex, JavaScript-heavy websites? Simple browser extensions excel at smaller tasks, whereas platforms like Diffbot or Content Grabber are built for high-volume, complex data operations.
- Budget and Scalability: Your financial resources will guide your choice. Many tools, including Web Scraper and ParseHub, offer robust free tiers perfect for small projects. As your needs grow, you'll need to evaluate the pricing models of more advanced services to ensure they align with your anticipated return on investment.
- Data Handling and Integration: What happens after the data is extracted? Consider whether you need a tool that can directly export to formats like CSV and JSON, or one that offers API access for seamless integration into your existing databases, CRM systems, or business intelligence platforms.
From Data Collection to Strategic Action
Ultimately, a web site data extractor is just the first step. The true value emerges when you translate the raw data into strategic insights and decisive actions. This means not only choosing the right tool but also implementing a process to analyze, interpret, and act upon the information you gather. The most successful teams are those that embed data extraction into their core workflows, creating a continuous feedback loop that informs strategy, optimizes operations, and uncovers new opportunities. Whether you start small with a simple browser extension or invest in a comprehensive enterprise solution, you are equipping your organization with a distinct competitive advantage in an increasingly data-driven world.
Ready to start extracting valuable data from any website in minutes, without writing a single line of code? Download the PandaExtract - Ultimate Web Scraper Chrome extension today. It is the perfect web site data extractor for users who need a powerful, intuitive, and efficient tool directly in their browser.
Published on